COMS 4995 Advanced Systems Programming
Intro to Containers
Virtual Machines (VMs) vs. Containers
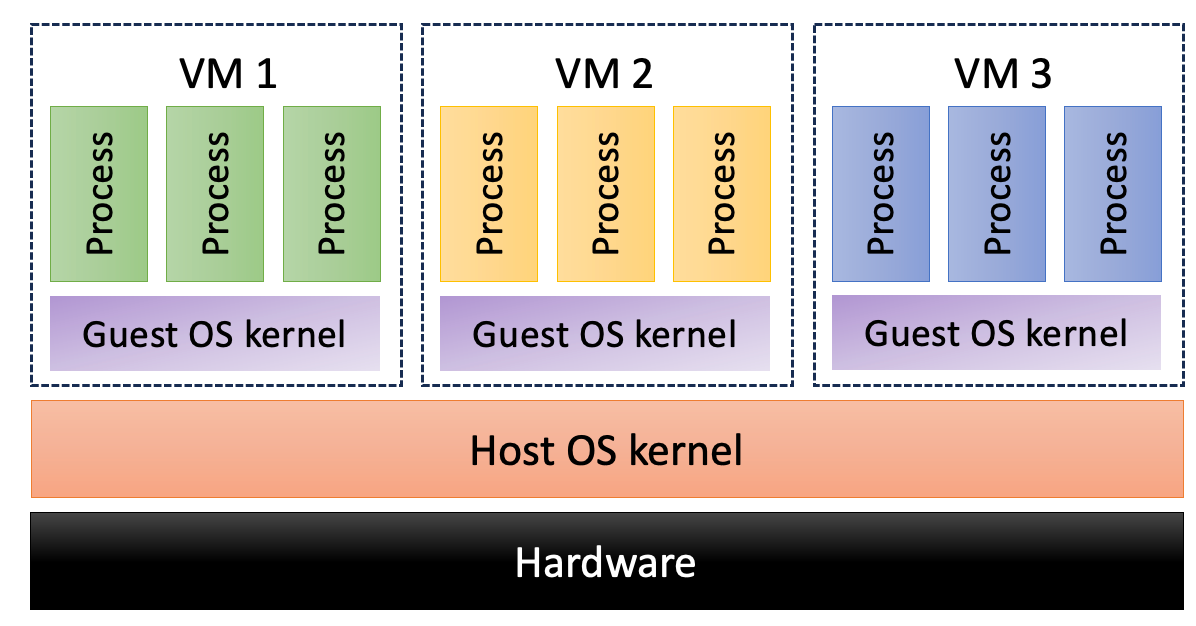
A VM is an instance of an operating system (guest OS) typically running on top of another operating system (host OS) controlling the actual hardware. A guest OS can run unmodified and does not need to communicate with the host OS. This approach is heavy-weight, has considerable hardware requirements, and can slow down the guest OS. A benefit of this approach is security due to strong separation between VMs.
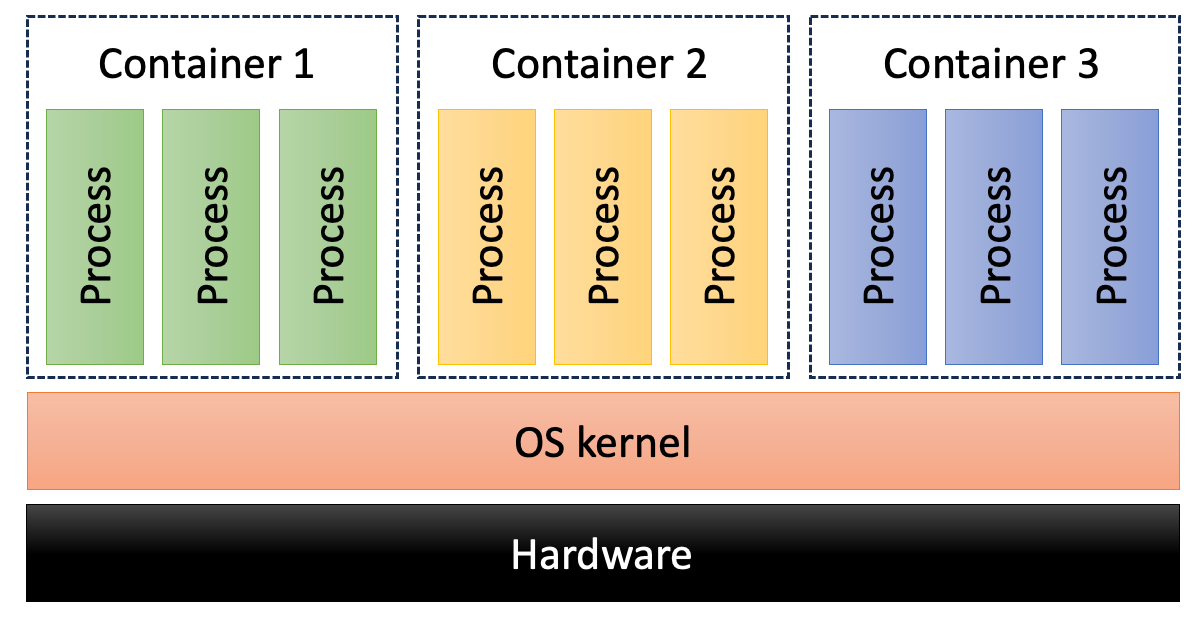
OS-level virtualization takes a completely different approach, where groups of processes appear to have a dedicated system, but share the OS kernel. This is the most efficient but least secure virtualization technique. In the Linux ecosystem, the term “container” is used to refer to OS-level virtualization.
A Linux container is a group of processes that has its own view of the underlying hardware and OS, independent of other containers or processes. The processes within the container can interact with each other, but usually cannot interact (or even see) processes in other containers.
Linux Containers
The Linux kernel has no notion of containers, only processes. Linux containers are a userspace abstraction built on top of several kernel facilities.
A LWN article writes:
The lack of a container abstraction in the kernel is seen as having enabled a great deal of innovation on the user-space side.
Userspace tools such as Docker or Podman hide the complexity involved with managing containers. However, once the container is set up, it is just a group of processes to the Linux kernel.
The following Linux kernel facilities are used to create containers:
- cgroups: Resource control
- Namespaces: Resource isolation
- Capabilities & seccomp: Kernel access control
cgroups
Linux control groups (cgroups) implements resource control, which is a set of mechanisms for tracking how much of a resource is being consumed by a set of process, what resources the process has access to, and imposing quantitative limits on the consumption.
cgroups are managed through the cgroupfs psuedo-filesystem mounted at
/sys/fs/cgroup. The demo below demonstrates how use cgroups to limit CPU usage
for a process.
$ cd /sys/fs/cgroup/
$ # List the controllers (knobs) that are available
$ cat cgroup.controllers
cpuset cpu io memory hugetlb pids rdma misc
$ # List the controllers that are active.
$ cat cgroup.subtree_control
cpuset cpu io memory pids
$ # Create a child cgroup
$ sudo su
# mkdir asp
# cd asp
# # By default, CPU usage is unbounded. Let's limit it to 20%.
# cat cpu.max
max 100000
# echo "20000 100000" > cpu.max
# # In another terminal, start up a cpu-bound process, such as `stress -c 1` and
# # monitor its CPU usage with `htop`. Once we add the process to this cgroup,
# # you'll see its CPU usage drop to ~20%.
# echo <pid> > cgroup.procs
# # Quit the cpu-bound process in the other terminal and remove the asp cgroup.
# cd ..
# rmdir asp
Namespaces
Linux namespaces add an additional layer to the naming of global UNIX resources. This is used to implement resource isolation, providing a set of processes with a private (virtual) view of selected global (OS-level) resources. The resources can include filesystems, process lists, network resources, etc.
We’ll use the unshare command to illustrate how to run a new process in
dedicated namespaces.
$ # --fork: Fork off /bin/bash
$ # --user: Create a new user namespace
$ # --pid: Create a new PID namespace
$ # --map-root-user: Map the current user to root in the new user nemespace
$ # --mount-proc: Create a new mount namespace and mount procfs in it so we
$ # can use `ps`
$ #
$ unshare --fork --user --pid --map-root-user --mount-proc /bin/bash
# # Note the user is root and the bash process ID is 1.
# ps uf
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 9200 5120 pts/9 S 22:55 0:00 /bin/bash
root 8 0.0 0.0 10464 3200 pts/9 R+ 22:55 0:00 ps uf
Running ps uf from another terminal shows an outside view of our “container”
containing the bash process. The bash process is running as a normal user jae
and has a different PID.
$ ps uf
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
jae 1896055 0.0 0.0 9236 5248 pts/16 Ss 22:53 0:00 -bash
jae 1959978 0.0 0.0 10464 3200 pts/16 R+ 22:55 0:00 \_ ps uf
jae 1893854 0.0 0.0 9236 5120 pts/9 Ss 22:53 0:00 -bash
jae 1938898 0.0 0.0 6192 1792 pts/9 S 22:55 0:00 \_ unshare --fork --user --pid --map-root-user --mount-proc /bin/bash
jae 1938900 0.0 0.0 9200 5120 pts/9 S+ 22:55 0:00 \_ /bin/bash
Capabilities & seccomp
Linux capablities and seccomp are used by the container to limit processes’ access to the Linux kernel. This added layer of security is necessary since all containers share the kernel and container processes, through user namespaces, can run as privileged users. Not all Linux system calls properly support namespaces, so the container must prevent processes from calling them.
Linux divides the privileges associated with the root user into distinct
categories called “capabilities”, which can be independently enabled and
disabled. See man capabilities for more details.
seccomp is a Linux facility which allows a process to transition into a “secure
computing state”. The seccomp() system call essentially takes an allowlist of
system calls that the process can make moving forward. See man seccomp for
more details.
Last updated: 2024-04-09